在上一篇文章中,我们介绍了三类基础知识蒸馏算法,今天我们一起来学习知识蒸馏的迁移学习应用。
前言
迁移学习定义及分类
迁移学习任务旨在将源域(source domain)上训练获得的预训练模型迁移至目标域(target domain)上,从而使模型在源域上学习到的知识能够迁移到目标域上,达到提升目标域任务表现等效果。
对于解决源域和目标域间的数据分布差异这一问题,根据迁移学习的实现对象目标区别 [3],可以将迁移学习方法分为如下类别:
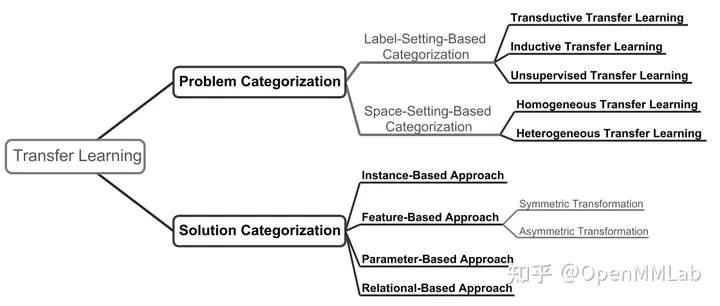
- 基于实例的迁移(instance-based transfer):即通过在源数据域(source data domain)中对实例采样进行调整或加权,使采样得到的数据分布接近于目标数据域(target data domain)的数据分布。
- 基于特征的迁移(feature-based transfer):即寻找新的特征表示和对应变换,将源域和目标域中模型所得到的特征变换到同一特征空间内再进行约束。
- 基于参数的迁移(parameter-based transfer):即在模型参数上直接进行源域模型(source-domain model)到目标域模型(target-domain model)的参数迁移和约束。
- 基于关系的迁移(relation-based transfer):即依赖于源域和目标域中存在的域内关系间的相似性进行迁移,近期工作较少。
蒸馏知识的迁移学习
蒸馏知识迁移中,一般将源域上训练的模型(source-domain model)作为教师模型,目标域上训练的模型(target-domain model)作为学生模型。
在迁移学习中,由于知识蒸馏在模型层面上进行,故知识蒸馏在迁移学习上的应用主要集中于基于特征的迁移(feature-based transfer)和基于参数的迁移(parameter-based transfer)。
其中,前文中我们介绍的知识蒸馏的三种基本方法可归类为基于特征的迁移(feature-based transfer):
- 基于分类预测软标签 logits(response-based)的知识蒸馏
- 基于中间层特征(feature-based)的知识蒸馏
- 基于样本或特征层间关系(relation-based)的知识蒸馏
蒸馏知识迁移的优点及应用领域
相对于基于实例的迁移(instance-based transfer)和基于关系的迁移(relation-based transfer),蒸馏知识迁移具有的主要优势如下:
- 无需依赖于源数据域和目标数据域间的数据分布差异特点或域内关系特点,也无需寻找相似数据分布的采样方式,提高数据域层面泛化性。
- 实行端到端知识蒸馏,便于对关键特征/输出进行约束。
- 去除源域和目标域间的数据域数据分布(data domain)和任务域下游任务(task domain)约束,得以实现跨数据域和跨任务的知识迁移。
因此,知识蒸馏在迁移学习中的应用集中于以下方面:
- 跨数据集的知识迁移(数据域):如图像分类任务中 CIFAR10 到 ImageNet1k 的迁移,高分辨率源域到低分辨率目标域上的模型迁移。
- 跨下游任务的知识迁移(任务域):如时空预测任务下人体动作预测子任务 KTH 数据集到降水预测子任务 HKO-7 数据集的迁移。
- 对于中间层特征具有高精度要求或对于中间特征层关系存在要求的下游任务迁移:如追求像素级精度的图像分割、视频注意力预测和降水预测任务,高分辨率源域到低分辨率目标域上的模型迁移。
本文将针对知识蒸馏在迁移学习上的两种应用方式:基于特征的迁移(feature-based transfer)和基于参数的迁移(parameter-based transfer),结合不同下游任务的算法工作,对知识蒸馏在迁移学习上的应用进行简介,为大家后续的深入研究、交流打下基础。
蒸馏特征的迁移学习(feature-based transfer)
蒸馏特征的迁移学习(feature-based transfer)通过在源域教师模型和目标域学生模型间寻找输出 logits 或中间层特征作为迁移目标的蒸馏知识,实现不同数据域和任务域间的教师—学生关系间的知识蒸馏。
对于下游任务相同的纯数据域迁移学习,蒸馏知识选取上一般包含软标签 logits 以利用非目标类的信息(response-based);对于跨任务域的迁移,蒸馏知识中常采用中间层特征(feature-based)。下面简单介绍相关算法工作实例和具体下游任务应用。
CRKD(TIP 2021)
除了前文中介绍的通过知识蒸馏进行模型压缩,对模型结构或通道进行压缩以节约计算存储开销外,降低图片分辨率也可大幅减少模型的计算和存储开销。
为了避免图片分辨率降低所带来的性能下降,以及弥补高低分辨率间的数据域分布差异,[CRKD](https://ieeexplore.ieee.org/abstract/document/9507362
) 提出了采用知识蒸馏进行高低分辨率数据域迁移的方法,将教师模型在高分辨率下的数据域学习的知识迁移至低分辨率数据域下的学生模型,从而达到模型压缩和分辨率降低的目标以共同削减模型计算存储开销。
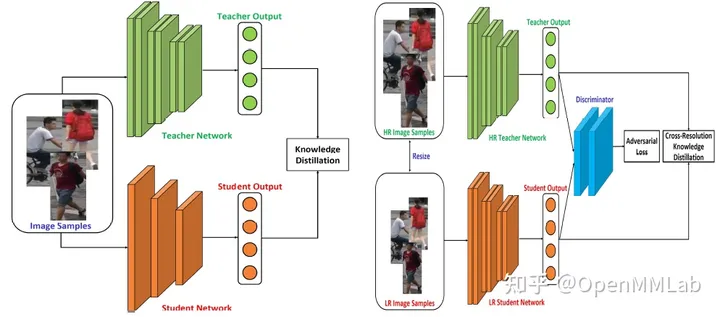

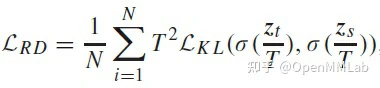
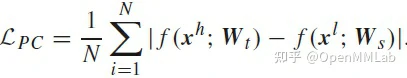
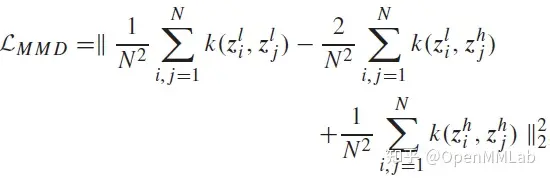

CRKD 在行人重识别、图像分类、人脸检测等子任务上都进行了相同任务域不同分辨率数据域的迁移实验,皆优于传统 KD 方法如 FitNet、ABLoss 等。
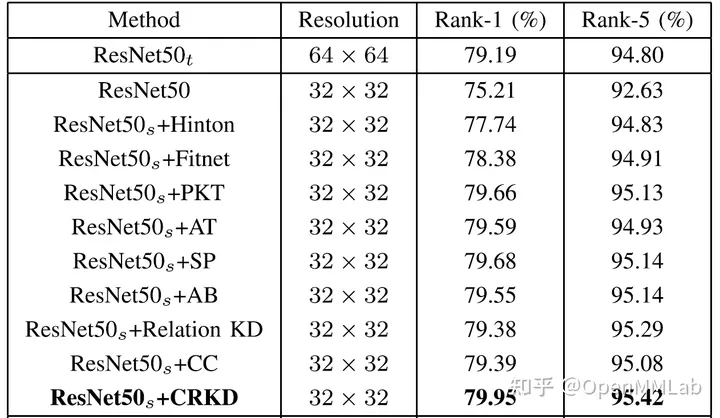
如下表,CRKD 在 CIFAR-100 数据集分类任务上经迁移后的低分辨率模型性能优于教师模型,证明其成功获得教师知识且从低分辨率数据域上获取额外多尺度空间信息。
AFD(AAAI 2021)
传统的对特征层的知识蒸馏中,由于教师模型和学生模型的网络通道数和结构差异,往往需要手动选取关键中间层特征或软标签输出 logits 建立关系,将关系的教师特征和学生特征作为蒸馏目标进行学习,并经过前文中介绍的 connector 进行不同尺寸特征层间对齐。然而,手动选择关系可能和实际特征间相关性存在差异,且任务域迁移导致的下游任务变化可能使手动选择关系的有效性降低。
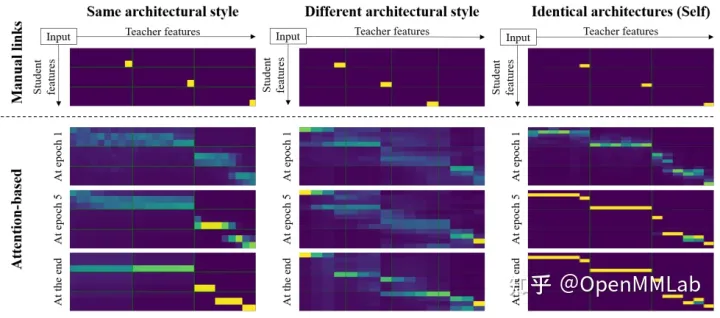
因此,AFD 便提出了采用注意力机制,根据特征间相似度对所有可能的教师模型和学生模型特征间关系进行加权调整的方法,从而动态调整教师模型和学生模型间的特征对应关系。
相比前文中介绍的强调教师特征和学生特征中特征内关系的 RKD(Relational Knowledge Distillation),AFD 强调教师特征和学生特征间的关系选取。
对于教师模型和学生模型间复杂的特征匹配对齐关系,有没有一个算法库可以简便地改变蒸馏过程中的师生特征选取关系,实现通过配置文件轻松调整特征对齐方式呢?
当然!MMRazor 库中实现了蒸馏算法中 蒸馏模型结构 distiller、蒸馏特征对齐模块 connector、特征信息传递 recorder、蒸馏损失 loss 的功能抽象解耦和可配置解析,让你可通过配置文件自由调整教师模型向学生模型迁移中的特征选取和特征对齐方式,并可轻松复用预训练好的模型结构参数及损失而无需为适配特征对齐特意修改!
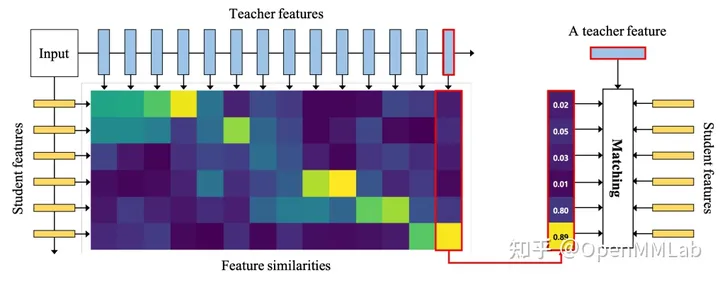
如图,对于教师模型和学生模型间的中间层特征差异,AFD 训练教师特征和学生特征间的相关性注意力,并将教师特征和注意力加权后的学生特征作为蒸馏目标。
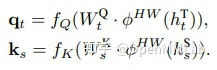
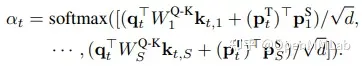

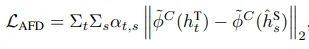
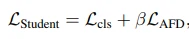

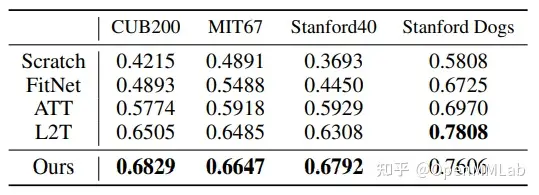
AFD 在知识蒸馏的模型压缩和迁移学习两个方向上都进行了实验,其中迁移学习上以图像分类 ImageNet 作为源域,分别以 CUB200 鸟类分类、MIT67 室内场景识别、Stanford40 人体动作识别、和 Stanford Dogs 狗类识别作为目标域进行迁移,实验结果如下表所示。
蒸馏参数的迁移学习(parameter-based transfer)
TMU(ICML 2020)
在源域向目标域的迁移中,考虑到数据分布和下流任务的差异,知识蒸馏的主要蒸馏目标和迁移对象一般为教师模型和学生模型中的特征或输出,从而间接隐式实现模型参数在参数源域到目标域的转换,直接显式进行模型参数的迁移工作较少。
然而,对于如 LSTM、GRU 等通过重要隐藏层状态参数 C 表达序列特征提取中模型记忆的教师模型,对参数进行显式迁移相比于对中间特征进行迁移存在如下优点:
- 不同于特征迁移,参数迁移将迁移部分在模型流程中同其他部分解耦,使得在目标域上进行 finetune 时无需使用全部教师模型。
- 对关键参数记忆状态直接进行迁移,使得多教师记忆库进行模型集成得以实现,可根据先验知识动态调整参与迁移的教师模型,且允许集成不同模型结构的教师模型而无需分别选取教师和学生特征间 connector 蒸馏关系。
- 存储关键参数而非整个教师模型,节约存储开销。
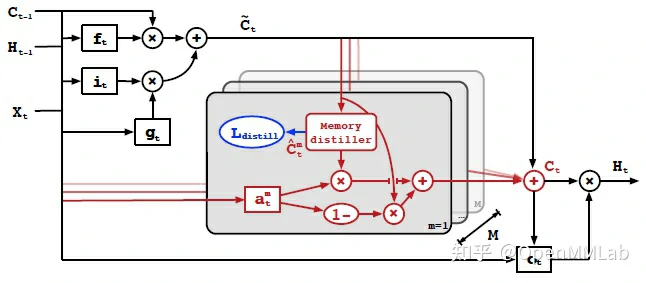
根据以上优点,TMU 针对训练时间长,存储计算开销大的像素级视频预测任务和不同数据集数据分布极大的降水预测子任务特点,提出了使用多个源域上预训练得到模型记忆库对目标域模型进行记忆蒸馏的无监督视频预测方法,直接对记忆参数进行蒸馏以便于多教师模型集成知识。
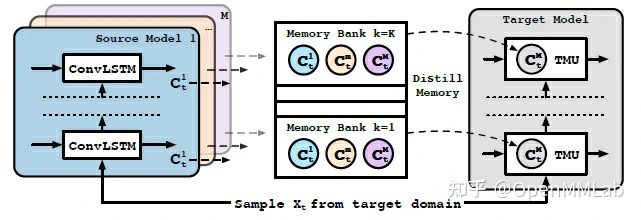
如图,TMU 将不同任务域不同数据域上进行预训练的模型记忆参数 C^m 抽离教师模型,作为教师记忆单独存储于 memory bank 中,使得在目标域上向学生模型进行知识迁移时无需使用整个教师模型。
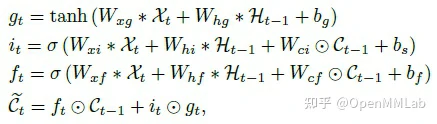

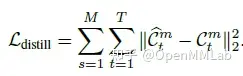

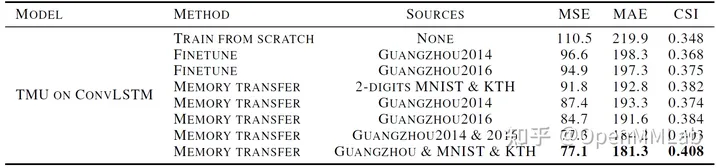
如下表所示,TMU 在视频预测任务的移动数字预测(Moving MNIST),人体运动预测(Human3.6M,KTH,Weizmann),降水预测(HKO-7,Guangzhou2014, 2016)等任务上进行了跨数据域跨任务域的实验。
值得注意的是,在降水预测任务中采用跨任务数据集(2-DIGITS MNIST & KTH)作为教师模型进行参数蒸馏的效果优于采用当前任务(降水预测)的广州数据集(GUANGZHOU2014, GUANGZHOU2016),说明 TMU 存在一定的跨任务迁移能力;同时,引入新的数据集不会导致预测结果下降,证实了 TMU 在知识蒸馏迁移参数时获得了额外学习能力。
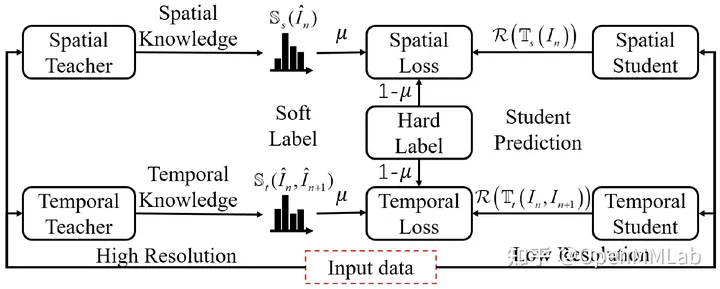
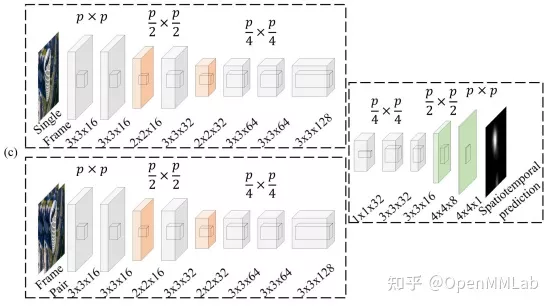
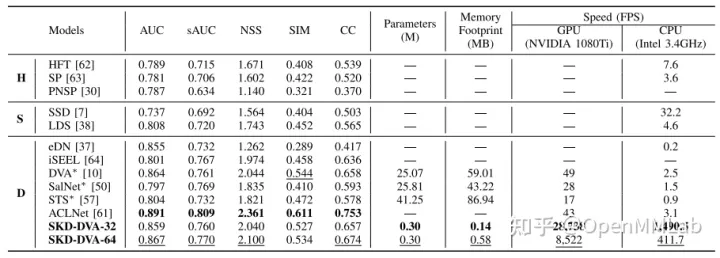
SKD(TIP 2019)


总结
本文对知识蒸馏在迁移学习中的应用进行了浅薄的介绍,主要为特征迁移和参数迁移两方面的工作,希望本文对大家在知识蒸馏和迁移学习的进一步研究有所帮助。
对于跨数据域、跨任务域迁移学习所涉及的诸多下游任务和数据集,有没有一个算法库可以简便地使用不同下游任务上不同数据集,避免繁琐的数据处理和接口对齐呢?
确实有! MMRazor 中实现了海量知识蒸馏算法,无缝衔接 OpenMMLab 框架中图像分类,目标检测,图像分割,人体姿态估计等主流 CV 下游任务。期待大家的使用与批评指正。
参考资料
https://zhuanlan.zhihu.com/p/591844966
[1] Yim J, Joo D, Bae J, et al. A gift from knowledge distillation: Fast optimization, network minimization and transfer learning[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2017: 4133-4141.
[2] Gou J, Yu B, Maybank S J, et al. Knowledge distillation: A survey[J]. International Journal of Computer Vision, 2021, 129(6): 1789-1819.
[3] Zhuang F, Qi Z, Duan K, et al. A comprehensive survey on transfer learning[J]. Proceedings of the IEEE, 2020, 109(1): 43-76.
[4] Li J, Fu K, Zhao S, et al. Spatiotemporal knowledge distillation for efficient estimation of aerial video saliency[J]. IEEE Transactions on Image Processing, 2019, 29: 1902-1914.
[5] Ji M, Heo B, Park S. Show, attend and distill: Knowledge distillation via attention-based feature matching[C]//Proceedings of the AAAI Conference on Artificial Intelligence. 2021, 35(9): 7945-7952.
[6] Dadashzadeh A, Whone A, Mirmehdi M. Auxiliary Learning for Self-Supervised Video Representation via Similarity-based Knowledge Distillation[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2022: 4231-4240.
[7] Yao Z, Wang Y, Long M, et al. Unsupervised transfer learning for spatiotemporal predictive networks[C]//International Conference on Machine Learning. PMLR, 2020: 10778-10788.
[8] Feng Z, Lai J, Xie X. Resolution-aware knowledge distillation for efficient inference[J]. IEEE Transactions on Image Processing, 2021, 30: 6985-6996.
[9] Zhu Y, Wang Y. Student customized knowledge distillation: Bridging the gap between student and teacher[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. 2021: 5057-5066.
[10] Park W, Kim D, Lu Y, et al. Relational knowledge distillation[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2019: 3967-3976.
[11] Yang L, Xu K. Cross modality knowledge distillation for multi-modal aerial view object classification[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2021: 382-387.
[12] Li X, Xiong H, Chen Z, et al. Knowledge Distillation with Attention for Deep Transfer Learning of Convolutional Networks[J]. ACM Transactions on Knowledge Discovery from Data (TKDD), 2021, 16(3): 1-20.
[13] Chen P, Huang D, He D, et al. Rspnet: Relative speed perception for unsupervised video representation learning[C]//Proceedings of the AAAI Conference on Artificial Intelligence. 2021, 35(2): 1045-1053.